-
2015-12-24
Sharding – What next?
In my previous post, I talked about the sharding feature – what it does, where it is useful, etc. You can read that post here: http://blog.gluster.org/2015/12/introducing-shard-translator. When we designed and wrote sharding feature in GlusterFS, our focus had been single-writer-to-large-files use cases, chief among these being the virtual machine image store use-case. We are happy …Read more
-
2015-12-23
Introducing shard translator
GlusterFS-3.7.0 saw the release of sharding feature, among several others. The feature was tagged as “experimental” as it was still in the initial stages of development back then. Here is some introduction to the feature: Why shard translator? GlusterFS’ answer to very large files (those which can grow beyond a single brick) had never been …Read more
-
2015-11-26
Usenix LISA 2015 Tutorial on GlusterFS
I have been working in GlusterFS for quite some time now. As you might know that GlusterFS is an open source distributed file-system. What differentiate Gluster from other distributed file-system is its scale-out nature, data access without metad…
-
2015-10-28
Highlights from LinuxCon EU: Bitrot detection in GlusterFS
Some quick highlights from our Gluster talks at LinuxCon EU, as well as slides available as a PDF below. Bitrot detection in GlusterFS – Gaurav Garg, Venky Shankar BitRot detection is a technique used to identify certain “insidious” type of disk errors where data is silently corrupted with no indication from the disk to the storage …Read more
-
2015-10-27
Highlights from LinuxCon EU: Gluster Automatic File Replication Talk
Some quick highlights from our Gluster talks at LinuxCon EU, as well as slides available as a PDF below. Gluster Automatic File Replication Talk from Ravishankar Narayankutty: The talk started off with a quick-start introduction to the gluster lingo and its keywords, relating them to a block-diagram representation of the components. It then went on to …Read more
-
2015-10-21
GlusterFS Case Study: RIS Belgium
Sometimes the solutions we put in place turn out even better than what we originally hoped. That could sum of the experience of Belgian Internet Service Provider RIS Belgium,which turned to Gluster to solve the problem of distributed storage and ended up getting more benefit from the solution than they expected. Initially RIS, a web …Read more
-
2015-10-20
Managing the World of the Small
 There is a growing discussion in the IT world about the ways in which we, as information technologists, will approach managing the world of the small.
There is a growing discussion in the IT world about the ways in which we, as information technologists, will approach managing the world of the small.There are two aspects of current technology that fall into this category of “small”–containers and the Internet of Things. Both technologies were the subject of two intriguing keynotes at the opening session of All Things Open yesterday.
It’s been no secret that Intel is keenly interested in the Internet of Things (IoT) of late, and Intel’s Director of Embedded Software in the Open Source Technology Center Mark Skarpness laid out a concise look at how the hardware computer company is approaching the promise of a world of interconnected IP devices.
Currently, there are three obstacles that Skarpness perceives as a barrier to IoT growth: a lack of knowledge in embedded systems, a lack of knowledge and implementation of best security, and determining the most efficient ways in which IoT devices can communicate with the cloud and each other. This last aspect is particularly tricky; presently, many IoT devices operate in a siloed fashion. one or many sensored devices will talk to a control device, which in turn will talk to master server in the cloud that will collect data or deliver optimized operation instructions. But Company X’s devices will usually only work with Company X’s systems. Not Company Y or Z. This situation has led to what some wags on the press have called “The CompuServe of Things.”
This is clearly a situation about which Skarpness and his colleagues are well aware, and he did not try to give it short shrift when he told his audience what the path to better IoT would be. Issues like connectivity and customization of IoT devices in terms of form factor and purpose were two major elements of Intel’s IoT plan moving forward, Skarpness said, along with the aforementioned need to lock such devices down.
It was the fourth element of Intel’s plan that particularly caught my attention: building control systems that provide device management within the unique IoT ecosystem. Not only are deployed IoT devices found in very high numbers (think swarm instead of farm), but they can also be hardware-frozen. If you have a number of sensors buried in the road, for example, you can’t just dig them out and update their onboard hardware. You may not even be able to update the software; some devices may be transmit-only, not receive.
Managing devices in such circumstances can be tricky at best. The numbers alone can be daunting; sensor-equipped devices can range in the tens of thousands and the amount of data produced can create a huge firehose of incoming data. Indeed, many of these issues may seem familiar to those wrestling with another “new” bit of technology: containers.
Like IoT devices, containers are also proving to be a challange to manage. Containers and the microservices they host are not so much managed as orchestrated, according to the next keynote speaker, Sarah Novotny, Head of Developer Relations at NGINX.
Novotny referenced Skarpness’ outline of IoT concerns in her discussion of how information technologists should be approaching the future.of technology. Novotny’s talk highlighted Alan Gopnik’s 2011 New Yorker article “The Information,” which decribed how people then viewed the influence of the Internet on their lives: “call them the Never-Betters, the Better-Nevers, and the Ever-Wasers.” Novotny skillfully weaved these terms into the ways in which we view current technologies, including containers.
For containers, the “Better-Nevers” would look at the problem of managing containers and highlight the huge complexities in dealing with app-centric tools that in some cases, may only have a mayfly-like lifespan. The “Never-Betters” may see the positive benefits of microservices and realize that their benefits will outweigh the costs.
This may very well be true, but whatever your outlook, the challange of maintaining a cohesive form of management in container or IoT space is very real. As powerful as tools like oVirt, RDO, and ManageIQ may be, they are designed for managing whole machines (real or virtual), not potentially millions of containers or inerconnected hardware devices. This is why you see such emphasis placed on projects like Atomic, which are a new step towards a world where managing the small is even more of a critical need than managing the large.
This is a case of art (as technology) imitating life. Our tools are becoming reflections of our biology: where untold billions of microsystems make up the macrosystems we call the life we see around us. The transition won’t be easy, but the path to this kind of system deployment seems clear. It is fortunate the innovation that’s inherent in open source will help speed things along.
This article originally appeared on
community.redhat.com.
Follow the community on Twitter at
@redhatopen, and find us on
Facebook and
Google+. -
2015-10-13
Introducing the OSAS Community Dashboard
Red Hat’s Open Source and Standards (OSAS) group, working with Bitergia, is capturing interesting data from some of the upstream projects with which Red Hat is deeply involved. On this page, you’ll find various vital signs from projects like oVirt, RDO, ManageIQ, and Gluster.
It’s useful for folks who are familiar with an open source project to be able to see, at a glance, the general trends for things like mailing list activity, IRC discussions, or how many bugs/issues are being opened and closed.
Why We Collect Statistics
Overall, you hope to see more developer activity in projects, an upward trend in mailing list discussions and participants, and a healthy number of issues being opened–and closed–in the project’s bug tracker. Over time, numbers can fill in an important part of the story of a project.
It is, however, worth noting that numbers can be misleading. A lull in mailing list activity might be a sign that a project is slowing–or it might just be a sign that developers are heads-down working and being less chatty than usual. (Or it’s vacation season.) Lots of chatter in IRC might be a sign that a project is busy, or they might be discussing the World Cup extensively. (Or both!)
What you don’t see in the charts is the nature of discussions, whether discussions are productive or not, and how much actual work is being accomplished. For that, we have to be involved in the projects on a day-in, day-out basis.
Apples and Oranges
Another word of warning before perusing the stats – comparing raw numbers for two dissimilar projects is not a valid way of measuring the health of two projects. For example, oVirt and RDO have different target audiences, and are at different stages of maturity. Comparing the growth in a “mature” community and a younger community is like comparing the vital signs and growth charts of a toddler and a young adult. If a toddler is showing rapid growth, that’s to be expected. You don’t really expect a 25-year-old to gain a few inches between checkups. (In fact, it’d be weird if they did–and possibly alarming!)
The only real way to judge a project’s health is by measuring it against itself over time, and knowing about the project’s long-term mission and goals.
More to Come
What you’re seeing on the dashboard today isn’t the final word on how we measure our project’s success. We’ll be continuing to look for ways to gather, and share, information about our projects. Have ideas? We’d love to hear from you!
This article originally appeared on
community.redhat.com.
Follow the community on Twitter at
@redhatopen, and find us on
Facebook and
Google+. -
2015-10-12
Linux scale out NFSv4 using NFS-Ganesha and GlusterFS — one step at a time
NFS-Ganesha 2.3 is rapidly winding down to release and it has a bunch of new things in it that make it fairly compelling. A lot of people are also starting to use Red Hat Gluster Storage with the NFS-Ganesha NFS server that is part of that package. Setting up a highly available NFS-Ganesha system using …Read more
-
2015-10-09
GlusterFS at LinuxCon Europe 2015
We’ve just wrapped up a great week at LinuxCon Europe 2016 in Dublin with a great showing from the Gluster community! BitRot Detection in GlusterFS – Gaurav Garg, Red Hat & Venky Shankar Advancements in Automatic File Replication in Gluster – Ravishankar N Gluster for Sysadmins – Dustin Black Open Storage in the Enterprise with …Read more
-
2015-10-07
Automating closing bugs on end-of-life versions of glusterfs
closing a lot of bugs in bugzilla through the (Red Hat) bugzilla web site is a royal pain in the a**. So— 1) get the bugzilla CLI utility: `dnf install -y python-bugzilla` (or `yum install python-bugzilla`) 2) sign in to bugzilla using your bugzilla account and password: `bugzilla login` 3) get a list of bugs …Read more
-
2015-10-02
Gluster News: September 2015
Since we did not have any weekly Gluster news go out in September, this post tries to capture and summarize action from the entire month of September 2015. == General News == GlusterFS won yet another Bossie in the open source platforms, infrastructure, management, and orchestration software category. Long time users of the project might …Read more
-
2015-09-22
Docker Global Hack Day #3, Bangalore Edition
We organized Docker Global Hack Day at Red Hat Office on 19th Sep’15. Though there were lots RSVPs, the turn up for the event was less than expected. We started the day by showing the recording of kick-off event. The … Continue reading →
-
2015-09-18
Silicon Valley Meetup at Facebook, September 2015
Facebook hosted a great crowd on Monday, September 14, in Silicon Valley with about 30 attendees and a full night of presentations about Gluster. We started by introducing our new Gluster Community Lead, Amye Scavarda. You’ll see her a lot more in the coming months promoting Gluster and the Gluster community. The talks started with …Read more
-
2015-09-10
Simulating Race Conditions
Tiering feature is introduced in Gluster 3.7 release. Geo-replication may not perform well with Tiering feature yet. Races can happen since Rebalance moves files from one brick to another brick(hot to cold and cold to hot), but the Changelog/Journal remails in old brick itself. We know there will be problems since each Geo-replication worker(per brick) processes Changelogs belonging to respective brick and sync the data independently. Sync happens as two step operation, Create entry in Slave with the GFID recorded in Changelog, then use Rsync to sync data(using GFID access)
To uncover the bugs we need to setup workload and run multiple times since issues may not happen always. But it is tedious to run multiple times with actual data. How about simulating/mocking it?
Let us consider simple case of Rebalance, A file “f1” is created in Brick1 and after some time it becomes hot and Rebalance moved it to Brick2.
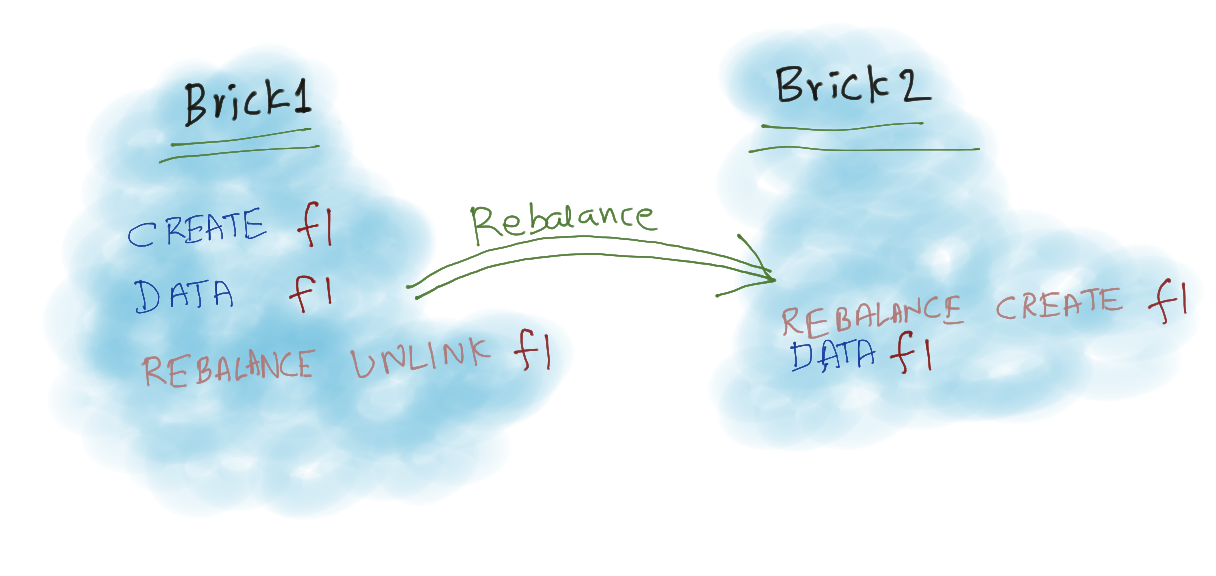
In Changelog we don’t capture the Rebalance Traffic, so in respective brick changelogs will contain,
# Brick1 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Brick2 Changelog DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef
If Brick1 worker processes fast, then Entry is created in Slave and Data Operation succeeds. Since Both the workers can independently, sequence of execution may be like
# Possible Sequence 1 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Possible Sequence 2 [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Possible Sequence 3 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef
We don’t have any problems with first and last sequence, But in second sequence Rsync will try to sync data before Entry Creation and Fails.
To solve this issue, we thought if we record CREATE from Rebalance traffic then it will solve this problem. So now brick Changelogs looks like,
# Brick1 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Brick2 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef
and possible sequences,
# Possible Sequence 1 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick2] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Possible Sequence 2 [Brick2] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 [Brick1] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef [Brick2] DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # and many more...
We do not have that problem, second CREATE will fail with EEXIST, we ignore it since it is safe error. But will this approach solves all the problems with Rebalance? When more FOPs added, it is very difficult to visualize or guess the problem.
To mock the concurrent workload, Collect sequence from each bricks Changelog and mix both the sequences. We should make sure that order in each brick remains same after the mix.
For example,
b1 = ["A", "B", "C", "D", "E"] b2 = ["F", "G"]
While mixing b2 in b1, for first element in b2 we can randomly choose a position in b1. Let us say random position we got is 2(Index is 2), and insert “F” in index 2 of b1
# before ["A", "B", "C", "D", "E"] # after ["A", "B", "F", "C", "D", "E"]
Now, to insert “G”, we should randomly choose anywhere after “F”. Once we get the sequence, mock the FOPs and compare with expected values.
I added a gist for testing following workload, it generates multiple sequences for testing.
# f1 created in Brick1, Rebalanced to Brick2 and then Unlinked # Brick1 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef # Brick2 Changelog CREATE 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1 DATA 0945daec-6f8c-438e-9bbf-b2ebf07543ef UNLINK 0945daec-6f8c-438e-9bbf-b2ebf07543ef f1
Found two bugs.
- Trying to sync data after UNLINK(Which can be handled in Geo-rep by Rsync retry)
- Empty file gets created.
I just started simulating with Tiering + Geo-replication workload, I may encounter more problems with Renames(Simple, multiple and cyclic). Will update the results soon.
I am sharing the script since it can be easily modified to work with different workloads and to test other projects/components.
Let me know if this is useful. Comments and Suggestions Welcome.
-
2015-08-19
Welcome to the New Gluster Community Lead
The Open Source and Standards team in Red Hat is very pleased to announce the addition of a new team member: Amye Scavarda, who will be taking the role of GlusterFS Community Lead.
Amye’s journey to the GlusterFS Project could arguably be said to hav…
-
2015-08-18
Thanking Oh-My-Vagrant contributors for version 1.0.0
The Oh-My-Vagrant project became public about one year ago and at the time it was more of a fancy template than a robust project, but 188 commits (and counting) later, it has gotten surprisingly useful and mature. james@computer:~/code/oh-my-vagrant$ git rev-list … Continue reading →

-
2015-08-04
Gluster Community Packages
The Gluster Community currently provides GlusterFS packages for the following distributions: 3.5 3.6 3.7 Fedora 21 ¹ × × Fedora 22 × ¹ × Fedora 23 × × ¹ Fedora 24 × × ¹ RHEL/CentOS 5 × × RHEL/CentOS 6 × × × RHEL/CentOS 7 × × × Ubuntu 12.04 LTS (precise) × × Ubuntu …Read more
-
2015-07-31
Build your own NAS with OpenMediaVault
OpenMediaVault is a Debian based special purpose Linux Distribution to build a Network Attached Storage (NAS) System. It provides an easy to use web-based interface, Multilanguage support, Volume Management, Monitoring and a plugin system to extend it …
-
2015-07-23
Git archive with submodules and tar magic
Git submodules are actually a very beautiful thing. You might prefer the word powerful or elegant, but that’s not the point. The downside is that they are sometimes misused, so as always, use with care. I’ve used them in projects … Continue reading →
